Как сделать парсер сайта самостоятельно (текстовая инструкция +видео)
|
Парсинг - это процесс извлечения информации из сайтов. Научиться этому можно достаточно быстро, 30-40 минут достаточно чтобы понять принципы и потом использовать этот навык для повседневной работы. Соответственно, многие хотят научиться создавать парсеры самостоятельно. Например, для тех, кто самостоятельно делаем автоматизацию в интернет-магазинах, часто нужно делать парсинг интернет-магазинов: выгрузить картинки или описания товаров (с характеристиками) с сайта поставщика. |
Перейти в парсер |
Чему вы научитесь, используя эту инструкцию?
1) самостоятельно делать простые парсеры.
2) массово выгружать информацию из категорий товаров.
3) выгружать данные в файлы YML,Excel,CSV,JSON.
Видео-инструкция по созданию парсера
Создадите настройку для нового парсера

На следующем шаге введите ссылку на карточку товара и на категорию
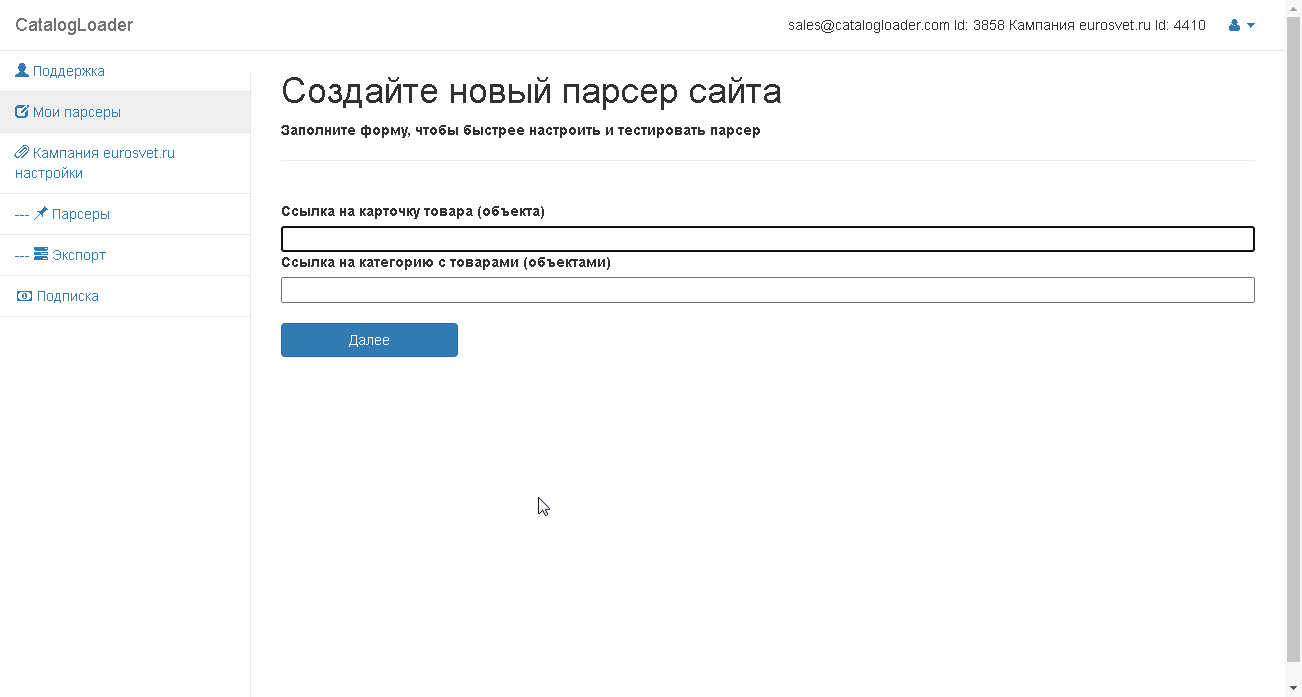
Для примера ввели ссылки для сайта eurosvet.ru
Карточка товара
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
Ссылка на категорию
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
и нажмите на кнопку "Далее"
и вы попадете на страницу где будет настраиваться парсер для вашего конкретного сайта.
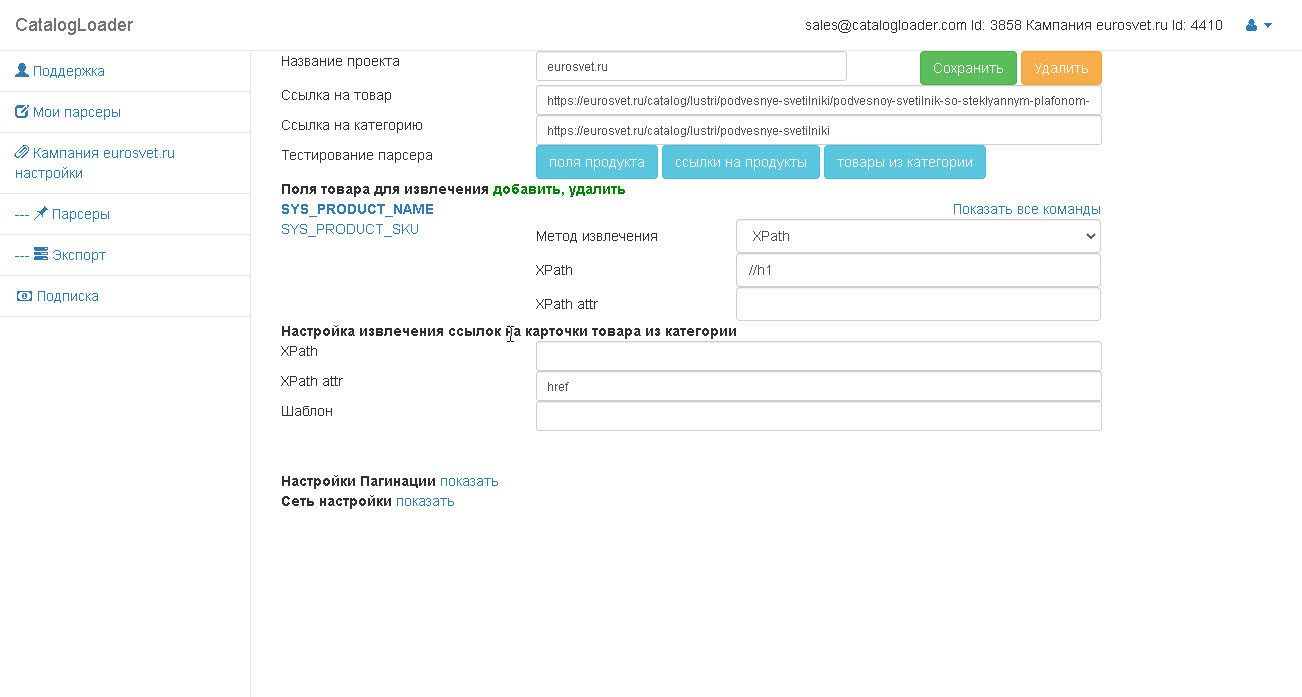
Настройка парсера
Можно выделить следующие этапы в настройке парсера сайта:
1. Настройка извлечения полей для конкретного продукта.
2. Настройка извлечения ссылок на карточки товаров из категории.
3. Настройка пагинаций (на английском pagination).
1. Настройка извлечения полей для конкретного продукта.
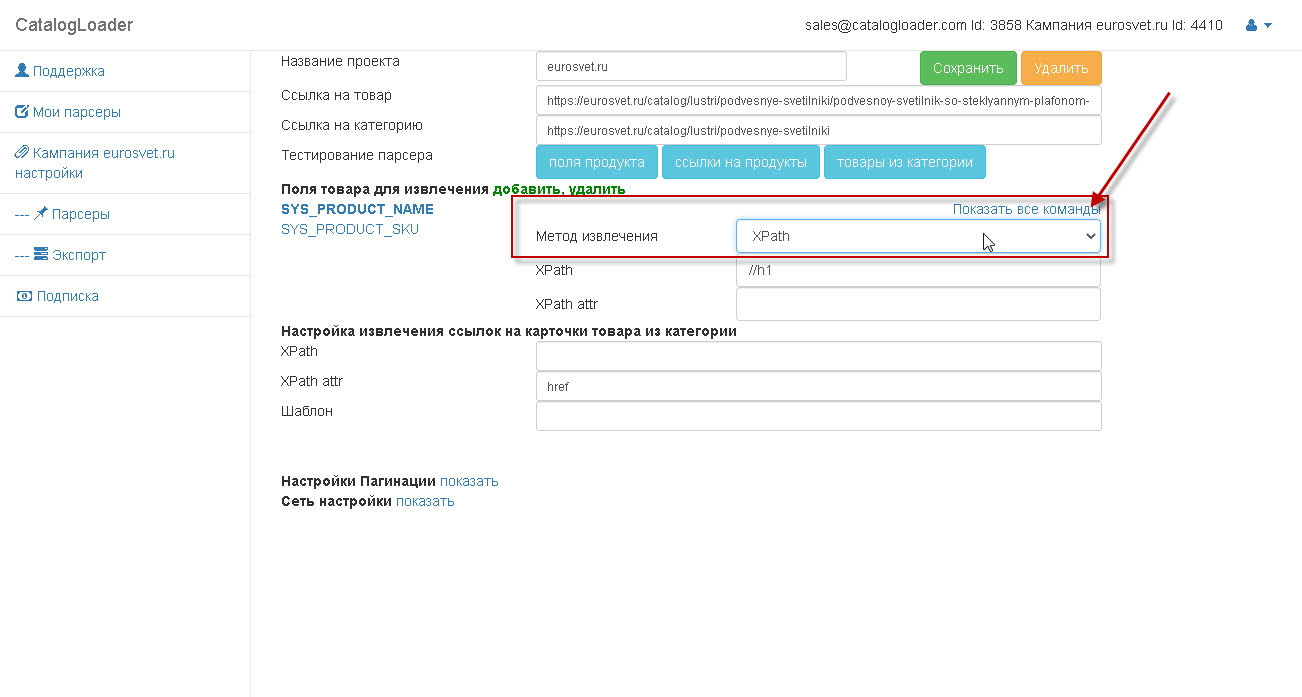
Важно! как только вы настроили поле, то тестируйте его извлечение через кнопку "Поля продукта".
И вы увидите как отработает парсер для вашего продукта.
Блок, который отвечает за извлечение полей - отмечен на картинке:
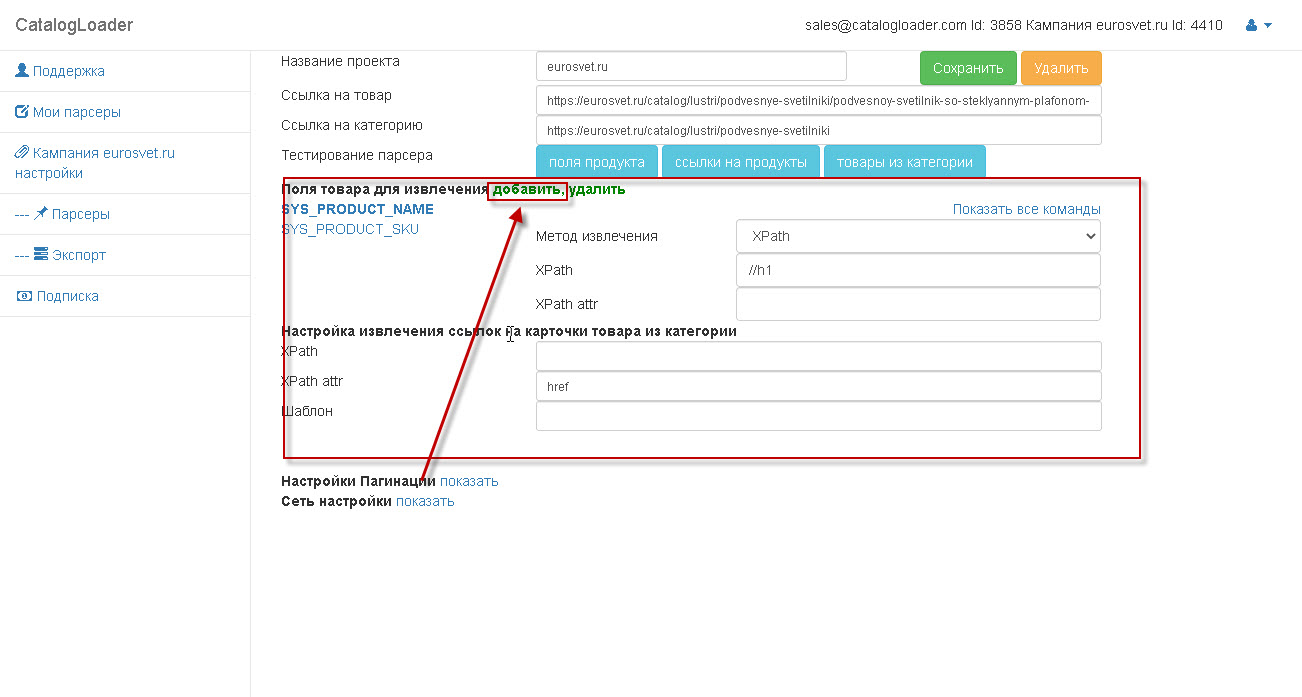
чтобы добавить новые поле -нажимайте на кнопку "добавить", если надо удалить,то ,сперва, надо выделить соответствующее поле, а потом кликнуть на соответствующую кнопку.
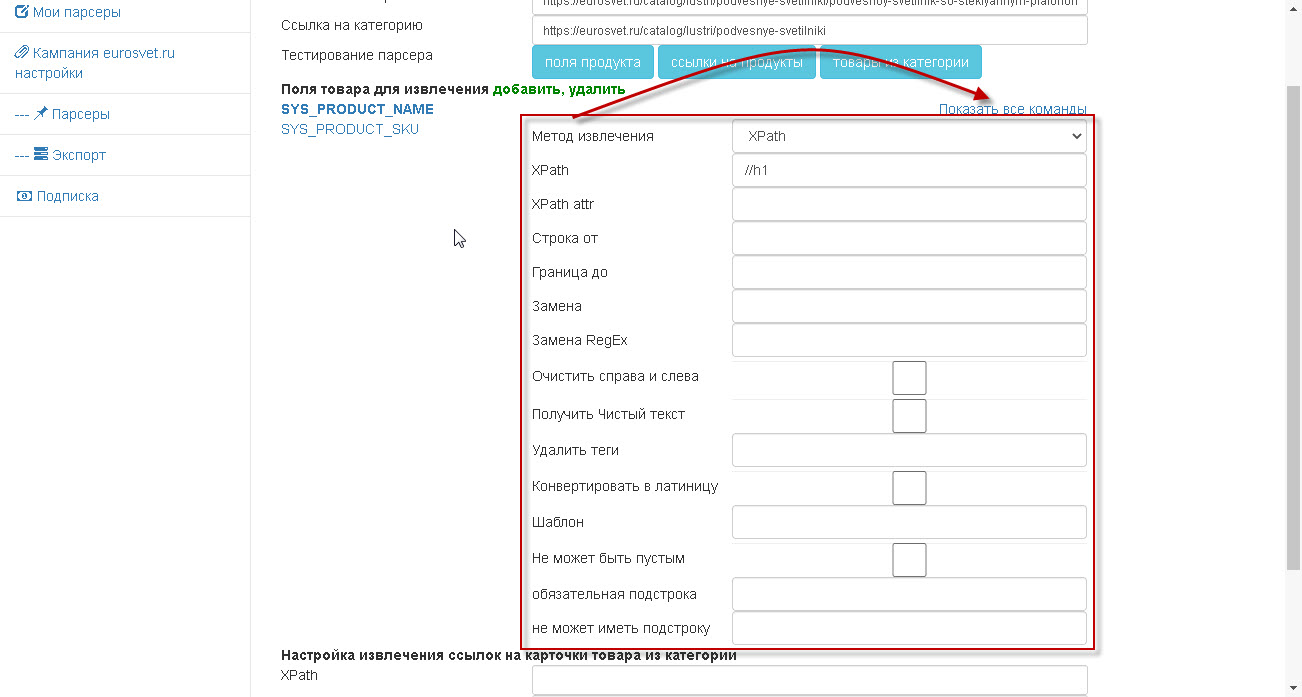
На следующей картинке показан диалог добавления новых полей.
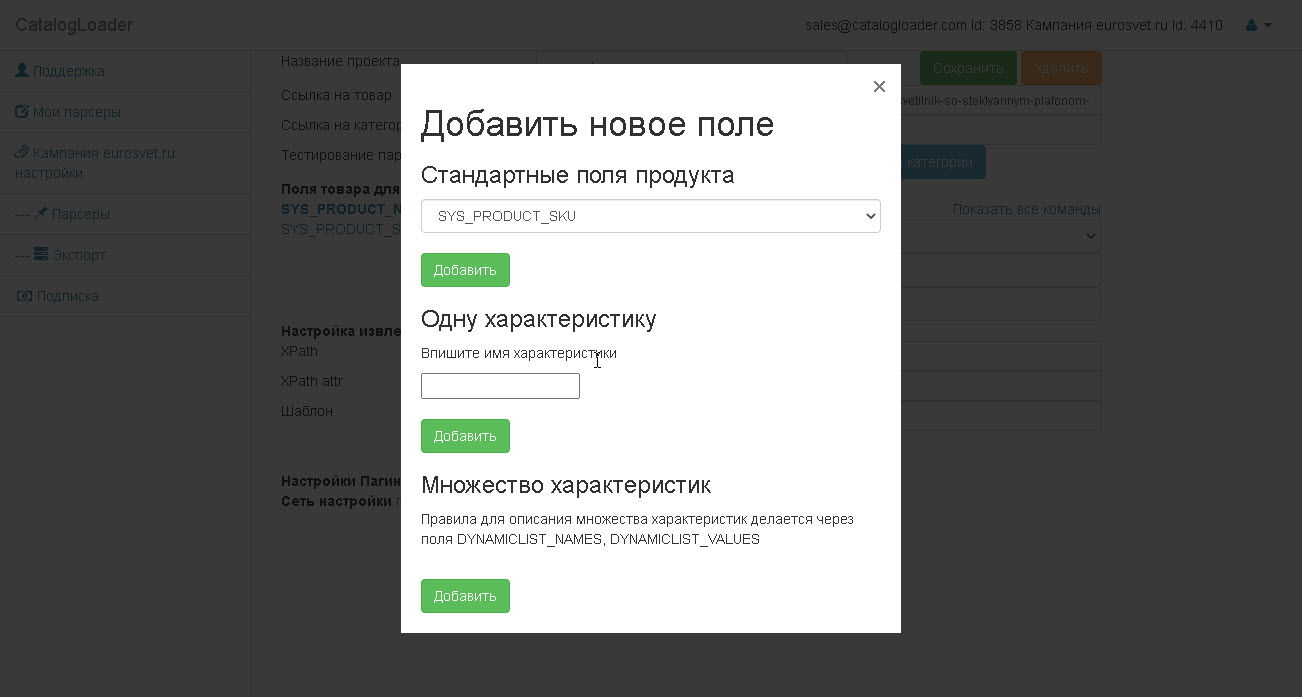
Есть 3 вида полей.
1) простые(базовые). - SYS_PRODUCT_SKU, SYS_PRODUCT_NAME, SYS_PRODUCT_MANUFACTURER и т.д.
это соответствунно Артикул, имя и производитель товара.
SYS_PRODUCT_IMAGES_ALL - это поле куда должно быть записаны все картинки продукта.
2) характеристики.-определяются характеристики товара, например, название вы можете задать самостоятельно.
3) динамические характеристики. Это тоже задает извлечение характеристик из таблицы значений.
для этого нужно будет задать DYNAMICLIST_NAMES, DYNAMICLIST_VALUES поля таким образом чтобы количество извлекаемых названий и значений было одинаково.
Как извлекать значения
Для любого поля можно указать как оно будет извлекаться.
Есть два варианта:
1)Xpath
2)RegEx (Regular Expresstion)- регулярное выражение.
дополнительно к командам можно добавить дополнительную обработку.
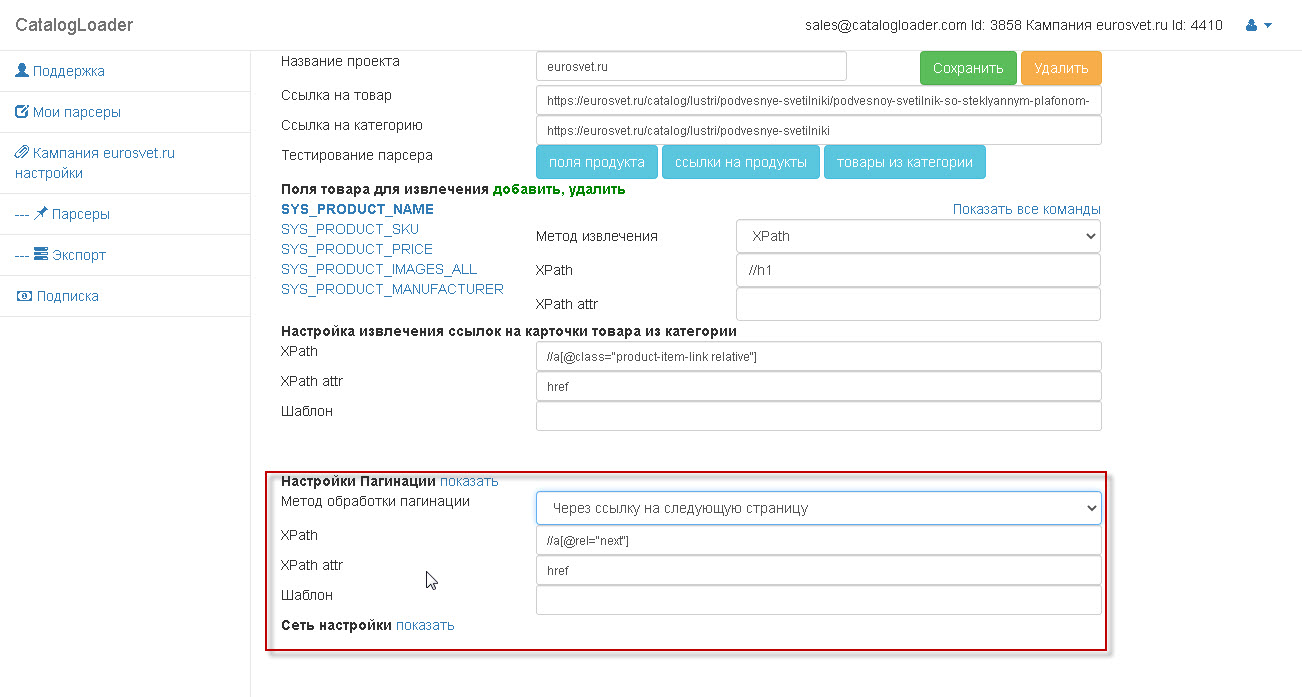
2. Настройка извлечения ссылок на карточки товаров из категории.
Важно! как только вы настроили "извлечение ссылок на карточки продуктов из категории", то тестируйте его извлечение через кнопку "ссылки на продукты". И вы увидите как отработает парсер для вашей категории. Ссылки соберутся без пагинаций.

поле "Шаблон" в этой области нужно для того чтобы задать абсолютный путь для ссылки,если это необходимо. Обычно оставляется пустым.
3. Настройка пагинаций (на английском pagination).
Если вы уже дошли до этого шага, то это значит что вы уже сделали 90% работы. После завершения настроек по пагинации чтобы протестировать парсер надо будет нажать на кнопку "товары из категории".
есть два варианта как настраивать пагинацию
1. через шаблон

2. через "следующую ссылку"
Что такое "следующая ссылка" вам поможет понять следующее изображение:
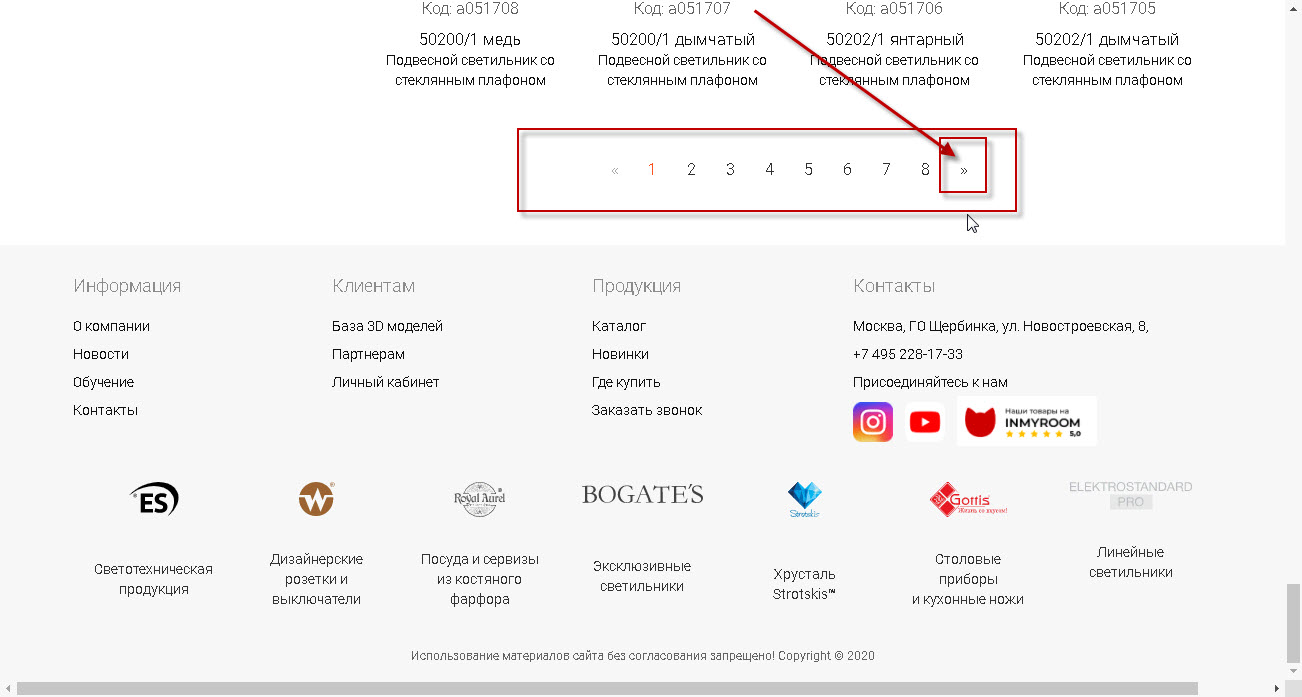
т.е. та ссылка, которая определяет переход из текущей страницы каталога на следующую.
Как запускать парсер
Есть два способа:
1) из настроек парсера, путем нажатия на кнопку "товары из категории"
2) из вкладки "Экспорт", путем нажатия на кнопку "запустить экспорт"
два этих способа предложат вам следующий экран, на котором надо будет задать откуда брать "входные" ссылки
для старта парсера
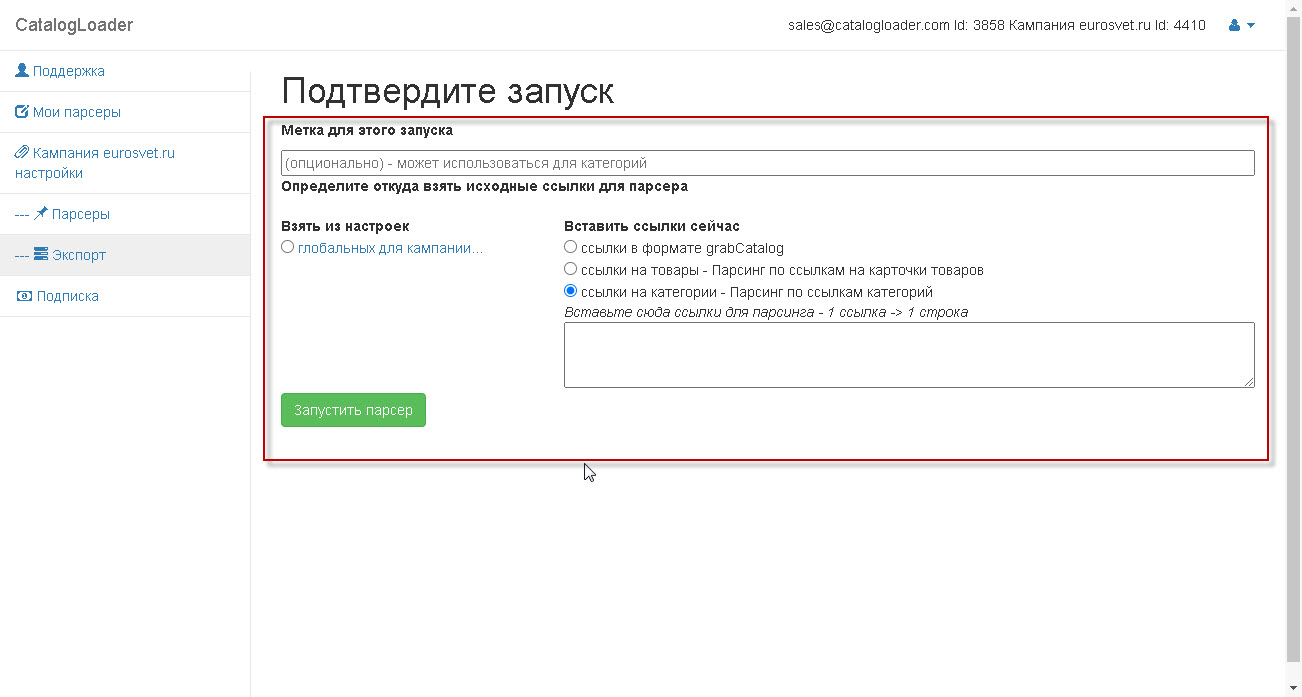
в самом простом варианте использования, вы на каждый запуск определяет ссылка или на карточки товаров или на категории,выбирая соответствующий режим работы.
Если надо задать статический список или карточек товаров или категорий, то для этого надо задать grabCatalog файл через глобальные настройки кампании один раз, а потом уже использовать каждый следующий раз вручную или через запуск по-расписанию парсера.
Что такое grabCatalog формат
Это текстовый файл, который определяет
1)иерархию категорий, которая будет извлекаться
2)названия и ссылки (опционально) на категории, которые будет извлекаться
3)ссылки на карточки товаров (опционально).
важно знать о формате
# - (знак Решетка) - определяет уровень иерархии
[path] - отделяет имя категории от ссылки на категорию
пример : 1 категория будет парсится
пример : 2 категории будет парсится
#Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : 2 категории будет парсится, но они заданы как подкатегории 1 категории верхнего уровня.
##Подвесные светильники[path]https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
##Потолочные светильники[path]https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki
пример : заданы 2 ссылки на продукт (задаются после названия категории).
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
https://eurosvet.ru/catalog/lustri/potolochnie-svetilniki/potolochnaya-lyustra-571-a052390
Как настроить выгрузку данных в определенный тип файла

Краткий Урок-введение в Xpath для парсинга сайтов с примерами.
Для выбора тегов и наборов тегов в HTML документе XPath использует выражения путей. Тег Извлекается следуя по заданному пути или по, так называемым, шагам.
Пример HTML файла
Для примера будет использоваться следующий HTML файл

Выбор тегов (как извлечь конкретные теги через XPath)
Чтобы извлечь теги в HTML документе, XPath использует выражения. Тег Извлекается по заданному пути. Наиболее полезные выражения пути:
| Xpath Выражение | Результат |
|---|---|
| имя_тега | Извлекает все узлы с именем "имя_тега" |
| / | Извлекает от корневого тега |
| // | Извлекает узлы от текущего тега, соответствующего выбору, независимо от их местонахождения |
| . | Извлекает текущий узел |
| .. | Извлекает родителя текущего тега |
| @ | Извлекает атрибуты |
Некоторые выборки по HTML документу из примера:
| Xpath Выражение | Результат |
|---|---|
| messages | Извлекает все узлы с именем "messages" |
| /messages | Извлекает корневой элемент сообщений Важно знать!: Если путь начинается с косой черты ( / ), то он всегда представляет абсолютный путь к элементу! |
| messages/note | Извлекает все элементы note, являющиеся потомками элемента messages |
| //note | Извлекает все элементы note независимо от того, где в документе они находятся |
| messages//note | Извлекает все элементы note, являющиеся потомками элемента messages независимо от того, где они находятся от элемента messages |
| //@date | Извлекает все атрибуты с именем date |
Предикаты
Предикаты позволяют найти конкретный Тег или Тег с конкретным значением.
Предикаты всегда заключаются в квадратные скобки [].
В следующей таблице приводятся некоторые выражения XPath с предикатами, позволяющие сделать выборки по HTML документу из примера
| Xpath Выражение | Результат |
|---|---|
| /messages/note[1] | Извлекает первый элемент note, который является прямым потомком элемента messages. Важно знать!: В IE 5,6,7,8,9 первым узлом будет [0], однако согласно W3C это должен быть [1]. Чтобы решить эту проблему в IE, нужно установить опцию SelectionLanguage в значение XPath. В JavaScript: HTML.setProperty("SelectionLanguage","XPath"); |
| /messages/note[last()] | Извлекает последний элемент note, который является прямым потомком элемента messages. |
| /messages/note[last()-1] | Извлекает предпоследний элемент note, который является прямым потомком элемента messages. |
| /messages/note[position()<3] | Извлекает первые два элемента note, которые являются прямыми потомками элемента messages. |
| //heading[@date] | Извлекает все элементы heading, у которых есть атрибут date |
| //heading[@date="11/12/2020"] | Извлекает все элементы heading, у которых есть атрибут date со значением "11/12/2020" |
Выбор неизвестных заранее тегов
Чтобы найти неизвестные заранее узлы HTML документа, XPath позволяет использовать специальные символы.
| Спецсимвол | Описание |
|---|---|
| * | Соответствует любому тегу элемента |
| @* | Соответствует любому тегу атрибута |
| node() | Соответствует любому тегу любого типа |
Спецсимволы, пример выражения XPath со спецсимволами:
| Xpath Выражение XPath | Результат |
|---|---|
| /messages/* | Извлекает все элементы, которые являются прямыми потомками элемента messages |
| //* | Извлекает все элементы в документе |
| //heading[@*] | Извлекает все элементы heading, у которых есть по крайней мере один атрибут любого типа |
Если надо выбрать нескольких путей
Использование оператора | в выражении XPath позволяет делать выбор по нескольким путям.
В следующей таблице приводятся некоторые выражения XPath, позволяющие сделать выборки по демонстрационному HTML документу:
| Xpath Выражение XPath | Результат |
|---|---|
| //note/heading | //note/body | Извлекает все элементы heading И body из всех элементов note |
| //heading | //body | Извлекает все элементы heading И body во всем документе |